What is Shadow AI? Five definitions, one Governance Problem

What is shadow AI? It depends on who you ask, and that ambiguity is the problem.
The label gets used in at least five different ways. Each one describes a real failure mode, each one points at a different control, and the choice of definition determines which tools you buy, which vendors you listen to, and which auditor question you cannot answer next quarter. No major standards body uses the term. Most of the people who do use it sell something that fixes one of the five problems and is blind to the other four.
This post does three things. It separates the five definitions and shows where each one breaks. It explains why none of NIST, ISO, or the EU use the label even though all three address the underlying issue. And it lays out what to do about shadow AI in your organisation this quarter, regardless of which definition your CISO and your head of data science are arguing about.
Shadow AI does not have a definition. It has five.
The term emerged in 2023 as shorthand for employees pasting work data into ChatGPT. It now covers entire workflows powered by autonomous agents. The scope crept that fast because the underlying anxiety, of running AI that nobody mapped, is real and recurring, and people kept reaching for the same label every time a new flavour of the problem appeared.
It turns out the same two-word phrase is doing the work of five distinct technical concepts.
Definition 1: Employees using unauthorised consumer AI tools
This is the original meaning, and the most common one in cybersecurity press. An employee opens a new browser tab, signs into a personal account on a public AI service, pastes in something that should not have left the building, and receives a useful answer. The data is now on a third-party server that your DPA does not cover and your contracts do not bind.
The April 2023 Samsung incident is the founding story. Engineers fed semiconductor source code into ChatGPT to debug it. The code was now training data for a model owned by another company. Samsung banned generative AI on company devices shortly afterwards. Every shadow AI article published since cites this incident or one like it, because the failure mode is intuitive and the example is concrete.
The problem here is data leakage. The control set is familiar: DLP, network inspection, browser policy, sanctioned alternatives that are good enough that employees stop reaching for the personal account. If you stop at this definition, you build a programme that catches the obvious cases and misses the four other categories entirely.
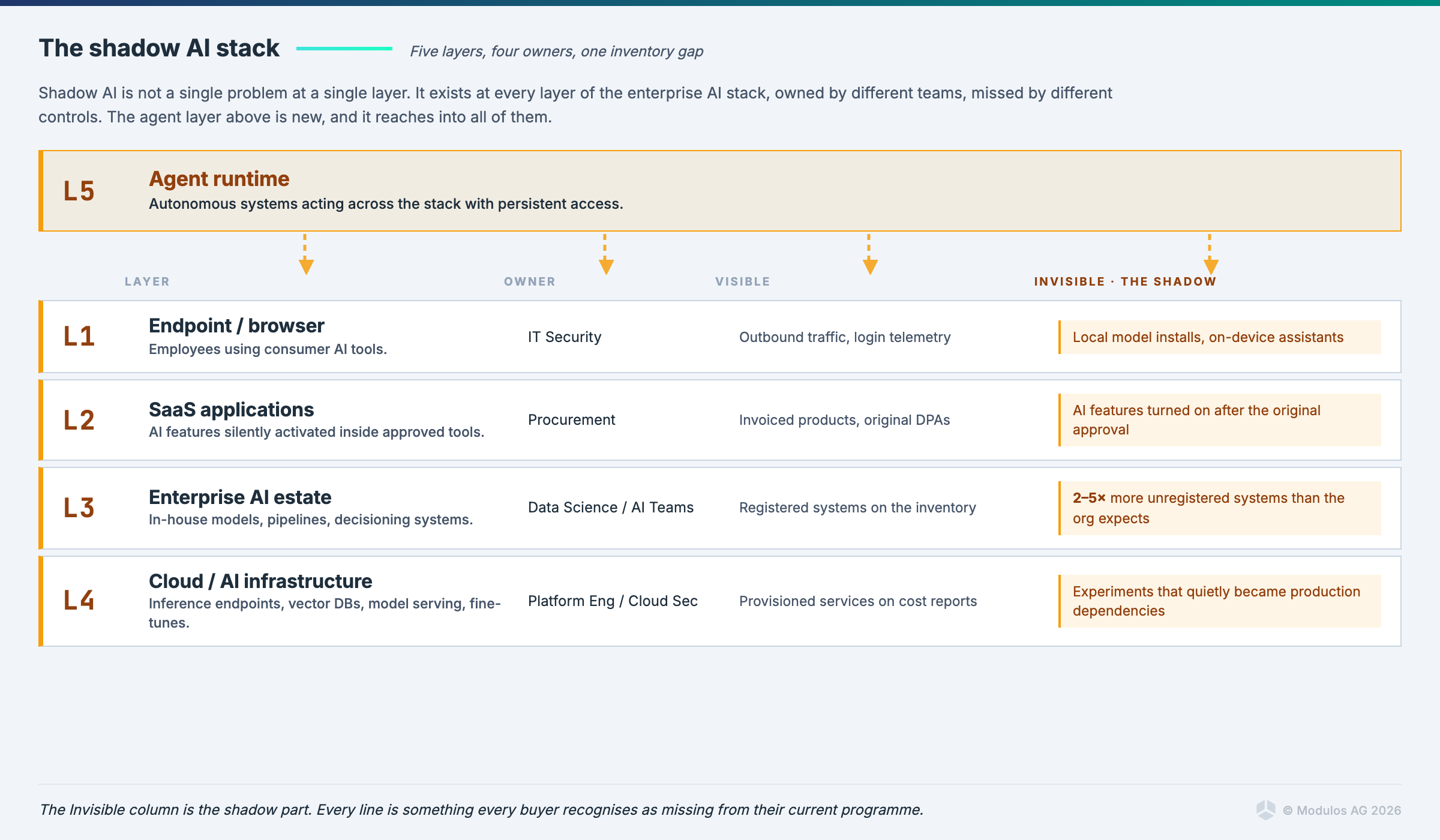
Definition 2: Ungoverned AI systems inside the enterprise
This is the governance professional's definition. Shadow AI here means AI models, pipelines, decisioning systems, and agents that exist somewhere inside your organisation without appearing in any central inventory. The marketing team's lead-scoring model. The procurement bot a department wired up to a third-party API. The fine-tuned classifier that has been quietly running in production for eighteen months because the team that built it left.
The problem is not that an employee did something they should not have. The problem is that nobody has visibility, nobody owns the risk, and nobody can answer the auditor's first question, which is always the same. How many AI systems do you have? Most enterprises that try to answer this question for the first time find they have between two and five times as many AI systems as they expected. The first inventory is always a shock.
The control set is structural rather than technical. AI inventory. Owner assignment. AI Bills of Materials describing each system's models, data sources, and dependencies. A registry that the rest of the governance programme can hang off. This is the definition we operate against at Modulos, because the EU AI Act, ISO 42001, and the NIST AI RMF all assume you have an inventory before any of their other requirements make sense.
Definition 3: AI features silently turned on inside approved software
This is the SaaS edge case, and it is structurally different from the other four. Your organisation already approved the productivity suite, the CRM, the design tool, the file-sharing platform. Twelve months later the vendor turned on a generative AI assistant inside the same product, often in a free preview, sometimes by default, occasionally without explicit notification.
Data that was previously stored in a SaaS tool is now being summarised, indexed, embedded, and in some cases used to train models. None of that was in your original procurement decision. Your security questionnaire predates the feature. Your DPIA is silent. The vendor's terms of service quietly updated.
This is sometimes called sneaky AI to distinguish it from employee-driven shadow AI, which is more accurate but worse marketing. The control set is contractual and procedural: AI clauses in vendor agreements, an obligation on suppliers to disclose new AI features before activation, a recurring SaaS audit specifically for AI capabilities, and a procurement process that treats material AI changes the way it treats material data processing changes. None of this is technical. All of it is governance work.
Definition 4: Developer-deployed AI infrastructure without security review
This is the cloud security definition. Engineers and data scientists with cloud credentials spin up the components of an AI stack on their own. An inference endpoint here. A vector database there. A fine-tuned model deployed for an internal experiment that quietly turned into a production dependency. None of it went through the security review that the same engineers would have triggered if they had asked for a new database or a new public-facing service.
The problem is attack surface. Misconfigured inference endpoints exposed to the public internet. Training data sitting in object storage with the wrong access policy. API keys for foundation model providers committed to repositories. Model files served without authentication. The well-understood failure modes of cloud security, applied to a stack that most security teams are still learning to inventory.
The control set lives in cloud security: posture management extended to AI workloads, asset discovery that knows what an inference endpoint looks like, attack-path analysis that includes model-serving infrastructure, and a build-time check that AI components went through the same review path as any other production service. If you only run the Definition 1 controls, you will not see this layer at all.
Definition 5: Autonomous agents operating outside governance
This is the newest definition and the one that breaks the previous four. An agent is not a model. It is a system that takes actions: it reads files, calls tools, sends messages, makes purchases, edits records. It accumulates persistent credentials. It maintains memory. It chains together capabilities that were never approved as a unit. The scope of an agent is the union of every tool you let it touch, and the audit question is no longer "what did the model output", but "what did the agent do, on whose authority, and how do we reconstruct it".
A growing fraction of agents inside enterprises today are running through Model Context Protocol servers that individual employees or developers stood up themselves. The MCP server connects the agent to email, to Slack, to file systems, to internal APIs. The agent is now a participant in your operational environment with permissions that nobody signed off on. When something goes wrong, and it will, the question of who is responsible runs into the question of whether anyone could have known the agent existed in the first place.
The control set has barely formed. Agent identity, in the sense of an account distinguishable from the employee who created it. Tool-call logging. Runtime behavioural monitoring that flags when an agent acts outside its mapped scope. An agent registry that lives next to the AI inventory and is treated with the same seriousness. The first legal paper arguing that high-risk agentic systems with untraceable behavioural drift cannot currently be placed on the EU market under the AI Act appeared in April 2026. The legal architecture is catching up faster than most enterprise programmes are.
Why every vendor's framing of shadow AI matches what they already sell
Read enough shadow AI content and a pattern becomes obvious. Network security vendors describe shadow AI as a traffic problem. Endpoint vendors describe it as an endpoint problem. Cloud security vendors describe it as a cloud posture problem. Data security vendors describe it as a data access problem. AI governance vendors describe it as an inventory problem. Each framing is internally consistent. Each one corresponds exactly to the product portfolio of the company doing the framing.
This is not a conspiracy. It reflects genuine differences in where each vendor has visibility, and visibility is destiny in security. The traffic vendor sees the prompts going out. The endpoint vendor sees the local model installs. The cloud vendor sees the misconfigured inference endpoint. The governance vendor sees, or fails to see, the absence of the AI inventory.
The cost of buying any single one of these as the answer to shadow AI is that the other four blind spots remain blind. The cost of buying all of them is a fragmented programme where five tools each catch one slice of the problem and no single dashboard tells you what is happening. The expensive lesson, repeated across every enterprise that has tried, is that no procurement decision substitutes for the underlying governance work. You need an inventory. You need owners. You need a control framework that the inventory and the owners hang off. Tools speed up parts of that programme. They do not replace it.
Why no standards body uses the term
NIST does not use it. ISO does not use it. The EU AI Act does not use it. None of NIST AI 600-1, ISO/IEC 42001:2023, or Regulation 2024/1689 contains the phrase shadow AI. This is worth pausing on, because the absence is informative.
Standards bodies write requirements that organisations have to operationalise and auditors have to assess against. A term whose meaning depends on the vendor speaking it does not survive that process. What survives is the underlying obligation: maintain an inventory of AI systems in scope, classify them by risk, assign ownership, document them, monitor them, and produce evidence that all of this is happening. The shadow AI problem is precisely the failure to meet this obligation. The standards do not need a label for the failure mode, because the requirement is that the failure mode does not exist.
The mapping is not subtle. NIST's four-function model has a Map function whose first action is identifying AI systems and their context. ISO 42001's Annex A includes controls for AI inventory, approved AI use cases, and lifecycle management. The EU AI Act requires providers and deployers to know what AI they place on the market or operate, classify it under Annex III, and produce technical documentation under Article 11. Every shadow AI category we listed is, under one of these frameworks, structural non-compliance. With fines under the AI Act reaching €35 million or 7% of global turnover, structural non-compliance is not a marketing concern. It is a board-level financial exposure that becomes enforceable in stages, with high-risk obligations applying from August 2026 in current law (see our analysis of the Omnibus trilogue for what is and is not moving).
ISO 42001 implementers describe their certification project, in private conversation, as the formal answer to the question of how you stop having shadow AI. That framing is closer to the truth than most of the vendor content on the topic. We covered what ISO 42001 actually requires in a separate post, written by the first vendor to take a governance platform through the certification.
Is shadow AI just shadow IT in new clothes?
This is the most common pushback against the term, and it deserves a serious answer. The shorthand version is that shadow AI is shadow IT with a fresh marketing budget. There is real truth in that. The dynamic is the same. Employees adopt tools the central IT function has not sanctioned, because the sanctioned alternatives are slower or worse, and the friction of getting an exception approved is higher than the perceived risk of going around the process. That dynamic produced shadow IT in the 2000s and shadow AI in the 2020s, with the same root causes.
What is genuinely new is what the tool does to the data once it has it. A SaaS application stores your data, processes it according to a contract you signed, and returns it to you when you ask. An AI tool reads your data, generates outputs from it, and in some configurations uses it to update model behaviour. Some of those updates are reversible, some are not, and the contractual position on which is which has not stabilised across the industry. The data is not just somewhere it should not be. It is participating in a learning process you did not authorise.
That distinction matters operationally because it changes what an incident looks like. A shadow IT incident usually ends with a list of accounts to deactivate and data to recover. A shadow AI incident sometimes ends there too, in the consumer-tool case. In other cases the data has already trained a model that has already produced outputs that have already been seen by other parties, and there is no clean recovery path. The remediation work is closer to a privacy breach than an access-control failure.
So the term is partly rebranding and partly a real distinction. The honest answer is that it is useful when it points at the AI-specific failure modes, and lazy when it is used as a synonym for "any new IT thing we did not approve". As with most terms that travel quickly, the question is not whether to use it but whether to insist on specifying which definition you mean.
How to detect shadow AI in your organisation
You will not detect shadow AI with one tool. You will detect it with a programme that combines five things, each one corresponding to one of the five definitions above. The categories that nobody runs are the categories where shadow AI accumulates.
Network observability for outbound traffic to known AI services. This catches Definition 1, employees pasting data into consumer tools. The detection is not perfect because traffic-based controls miss local model installs and on-device assistants, but it covers the bulk of the volume.
An AI inventory exercise that goes business unit by business unit and asks, with senior sponsorship, what AI is in use here. This catches Definition 2. The inventory is iterative. The first pass finds the systems people remembered. The second pass finds the ones they did not. The third pass finds the embedded AI in approved tools, which is Definition 3, and the developer-deployed components, which is Definition 4. Each pass has different prompts and different stakeholders.
A SaaS audit specifically for AI features in approved tools, repeated quarterly because vendors keep adding them. This catches Definition 3. The audit is partly contractual, asking suppliers to disclose AI activations, and partly observational, looking for new AI surfaces inside products you already have.
A cloud asset scan that knows what AI infrastructure looks like. Inference endpoints. Model files. Vector databases. Foundation-model API keys in code. This catches Definition 4. The same posture-management discipline applied to the rest of cloud, applied to the AI stack.
An agent registry and runtime monitoring for autonomous systems that take actions. This catches Definition 5, and most enterprises have not started yet. The agent registry is a 2026 build, not a 2024 build, and it is being built urgently inside the organisations that are honest about what they are running.
The shortest version: if you cannot answer the question of how many AI systems your organisation operates, and produce a list, with owners, you have shadow AI by Definition 2 regardless of how strong your network controls are.
How to prevent shadow AI
Prevention follows detection. The order matters because most organisations try to prevent before they have an inventory, which produces policies that nobody can comply with because they cannot identify the systems the policy applies to. The prevention work has four layers.
First, sanctioned alternatives that work. The fastest way to stop employees pasting data into a consumer AI tool is to give them an enterprise AI tool that does the same thing without the data exposure, with single sign-on, and without a six-week procurement loop. This is unglamorous. It also accounts for the majority of the volume reduction in the consumer-tool category.
Second, an inventory and a registry that are maintained, not produced. A snapshot inventory has a half-life of weeks. A registry that is updated whenever a new system is procured or built is a different artefact. The registry is the substrate that everything else hangs off, including the EU AI Act conformity assessment, the ISO 42001 audit, and the answer to the next board question about AI exposure.
Third, procurement and engineering processes that route AI decisions through a clear governance path. New AI feature in an approved SaaS product. New AI service deployed in cloud. New autonomous agent connected to a tool. Each of these has an owner, a checklist, and a default outcome. The default outcome is not that the system gets blocked. The default outcome is that it gets registered, classified, and assigned. Blocking is the exception. Registration is the rule.
Fourth, monitoring tied to the registry. The registry tells you what should be running. The monitoring tells you what is actually running. The delta is your shadow AI, by definition. This loop is what closes the gap, and the loop only works if the registry is real and the monitoring is current.
This is the operational answer to the question of how a governance programme functions. It is not the only answer, and the specific tools depend on your stack, but every working programme has these four layers in some form. The programmes that fail tend to fail because one of the four is missing or theatrical.
What to do this quarter
This week. Pick one definition you can defend as the dominant problem in your organisation right now. The honest answer is usually Definition 2, ungoverned systems, because most organisations have not done the inventory. Stop pretending you are working on all five at once.
This month. Do the inventory. Get senior sponsorship for it. Treat the first pass as a draft. Expect the count to surprise you. Identify the embedded AI in approved tools and the developer-deployed components as separate categories with their own owners.
This quarter. Stand up the registry as a maintained artefact. Wire it to procurement. Wire it to the ISO 42001 or NIST AI RMF programme that is going to need it as the input layer regardless of which framework you are aligning to. If you operate in the EU, run your inventory against Annex III of the AI Act and identify the systems that are about to become high-risk under the August 2026 timetable, or the December 2027 timetable if the Omnibus closes.
This year. Build the agent registry. Most enterprises are still in the position of pretending they do not have an agent problem. By the time the question is unavoidable, the agents will be embedded in too many workflows to inventory cheaply. Doing the work in 2026 is straightforward. Doing it in 2028 will be a cleanup project.
Closing
Shadow AI is what you call the failure mode of an AI governance programme that has not been built yet. The label is useful insofar as it gets the attention of executives who would not otherwise fund the inventory. It is misleading insofar as it suggests that buying one tool, in one of the five categories, fixes the problem. It does not. The fix is the programme: an inventory, owners, a registry, controls that the registry hangs off, and a loop that closes the gap between what should be running and what is.
The companies that do this work in 2026, while the regulatory deadlines are visible and the agent layer is still emergent, will run AI in 2028 with the same discipline they run financial controls. The companies that wait, and there will be many, will discover that shadow AI was the early symptom of a governance debt they kept refinancing until the bill came due. The bill is denominated in fines, audit findings, and the kind of incident that makes the press. It is also paid in slower AI adoption, because the systems you cannot defend are the systems you cannot deploy.
If you want a working session to map your current AI estate against the five definitions and identify the inventory work that pays back fastest, book a call with our team. The first inventory is the hardest. The second one is much easier. The third one is just the registry doing its job.
FAQ
What is shadow AI? Shadow AI describes AI systems, tools, or agents that operate inside an organisation without being registered, approved, or monitored by the relevant governance function. The label covers at least five different patterns, from employees using consumer AI tools through to autonomous agents accumulating access across enterprise systems. No standards body has formally defined the term.
What are the risks of shadow AI? The principal risks are data exposure to third-party model providers, regulatory non-compliance with frameworks like the EU AI Act and GDPR, security vulnerabilities in unmanaged AI infrastructure, and audit findings related to systems that should have been documented but were not. Under the EU AI Act, undocumented high-risk AI systems represent structural non-compliance subject to fines of up to €35 million or 7% of global turnover.
How do you detect shadow AI? Detection requires a programme rather than a single tool. The five components are network observability for outbound AI traffic, an AI inventory exercise across business units, a recurring SaaS audit for AI features in approved tools, a cloud asset scan that recognises AI infrastructure, and an agent registry with runtime monitoring. Each component catches one of the five categories of shadow AI; running fewer leaves predictable blind spots.
What are examples of shadow AI in the workplace? An employee using a personal account on a consumer AI service to summarise internal documents. A marketing team running a lead-scoring model that the data governance function never registered. A productivity tool quietly activating an AI assistant on data the procurement team approved before the feature existed. A developer deploying an inference endpoint without security review. An employee setting up an MCP server that connects an agent to email and internal APIs. All five are shadow AI, and each one has a different control answer.
Is shadow AI the same as shadow IT? The dynamic is similar, in that employees adopt tools the central function has not sanctioned. The technical risk is different, because AI tools generate outputs from data and in some configurations use it to update model behaviour, which produces incident patterns closer to a privacy breach than a typical access-control failure. Treating shadow AI as identical to shadow IT misses the AI-specific failure modes; treating them as entirely unrelated misses the shared root causes in procurement and IT culture.
How do you prevent shadow AI? Prevention has four layers: sanctioned AI alternatives that are good enough that employees stop reaching for personal accounts, a maintained AI inventory and registry, procurement and engineering processes that route AI decisions through a clear governance path, and monitoring tied to the registry so the gap between what should be running and what is running can be closed. Policies issued without an underlying registry tend to fail because there is no way to identify the systems the policy applies to.
Which standards address shadow AI? None of the major standards use the term, but all of them address the underlying problem. The NIST AI Risk Management Framework's Map function covers AI asset identification. ISO/IEC 42001:2023 includes controls for AI inventory and lifecycle management. The EU AI Act requires providers and deployers to know, classify, and document the AI systems they place on the market or operate. Building a governance programme on any of these frameworks structurally addresses shadow AI without ever using the label.


