AI governance assessment: why most of them have already failed

An AI governance assessment that ends with a PDF has already failed.
That statement annoys consultants, and that is fine. The reason it annoys them is that most of the market for AI governance assessments today produces exactly that output. A 60-page deliverable, a recurring retainer, and a file that gets referenced only when the next audit or the next board presentation forces it back into view.
Here is why this is a problem now, specifically, in 2026.
In March 2026, Modulos CEO Kevin Schawinski trained EU financial supervisors at the Supervisory Digital Finance Academy on operational AI governance. These are the people who will audit your AI programs on behalf of national competent authorities when the EU AI Act's high-risk obligations land. The first thing they were told to look for in an audited institution is a live inventory with evidence generated this quarter, rather than a policy document.
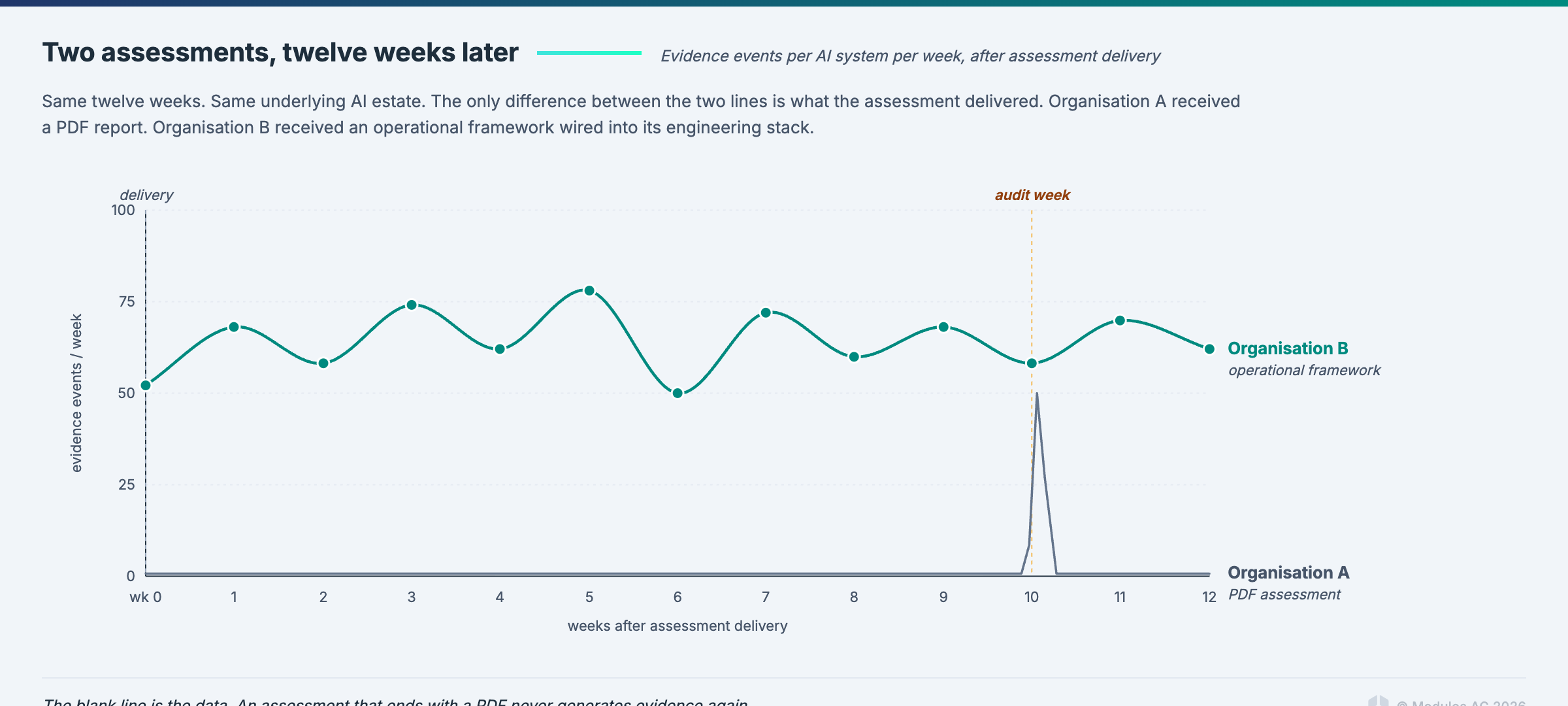
The assessment worth running is the first scan of a system that then stays lit. Everything else is a consulting deliverable masquerading as an engineering output.
What an AI governance assessment actually is
Strip the marketing off and an assessment is a structured scan of your AI systems against the frameworks you are accountable to.
The structured part matters. Random walk through your AI estate produces a catalogue, not an assessment. A structured assessment inventories the AI systems in use, classifies each by risk level, maps each against the requirements of the frameworks you are subject to, identifies gaps, and assigns ownership for closing those gaps.
The output is an evidence stream. It is not a report that goes in a filing cabinet; evidence streams run continuously and feed the controls that your supervisors will ask about next time they visit.
If the deliverable your assessment vendor hands you at the end is a bound document, you have bought a report. That is the first failure mode to recognise.
Why a one-shot AI governance assessment fails
Two failure modes, both fatal.
It goes stale in weeks, not months. AI systems change constantly; models get retrained, new agents come online, and SaaS vendors quietly ship AI features inside products your team already uses. Every one of those events invalidates a line in your static assessment. An assessment that reflected your AI estate four weeks ago is a historical document, not a governance artifact.
It does not produce the evidence supervisors now ask for. The new supervisory posture, in Europe and increasingly in the Gulf and East Asia, is operational. Supervisors ask for evidence generated this month. A PDF assessment from last year is not evidence of current governance, it is evidence that at some point in the past an assessment happened.
This is why the SOC 2 market is currently in the middle of a scandal. A $32 million compliance automation platform was recently exposed for producing hundreds of near-identical SOC 2 reports, the details of which were visible in an accidentally shared Google spreadsheet. Those reports looked like governance artifacts. They were documents. They did not survive contact with an actual question about whether the controls were operating. If the whole thing was exposed by an accidentally shared Google Spreadsheet, the assessment was fiction.
The same dynamic is about to unfold in AI governance. The organisations that bought fake assessments in 2024 and 2025 will discover that their supervisors want something different from what they purchased.
What an AI governance assessment must produce: the five required outputs
If your assessment does not produce all five of these, something is missing. Probably rigour.
1. Complete AI inventory, including what you cannot see. The visible systems are the ones on your registered model list. The invisible ones are the problem. More on this below.
2. Risk classification per system, against the frameworks you care about. Not a single label. A matrix. One system is high-risk under the EU AI Act, requires enhanced ISO 42001 controls, and sits in the NIST AI RMF Map / Measure quadrant that demands continuous monitoring. Classifying it once and forgetting is the mistake.
3. Gap analysis against named requirements, quantified. "We are 70% compliant with the EU AI Act" is a useless number. "We have closed 42 of 58 controls for high-risk systems under Chapter III, with €4.2M of annualised liability exposure on the 16 open controls" is a number that forces action.
4. Ownership and control assignment. Every gap closed belongs to a named person, with a named deadline, inside a named team. If the assessment leaves ambiguity about who owns what, it has produced nothing.
5. Evidence-collection plan. The mechanics of how the controls you assigned are going to produce evidence on a cadence, and what system that evidence will live in. Without this, the assessment terminates. With this, it becomes the seed of a governance program.
How to inventory AI systems honestly: the dark matter problem
This is where most AI governance assessments break structurally, so it is worth slowing down.
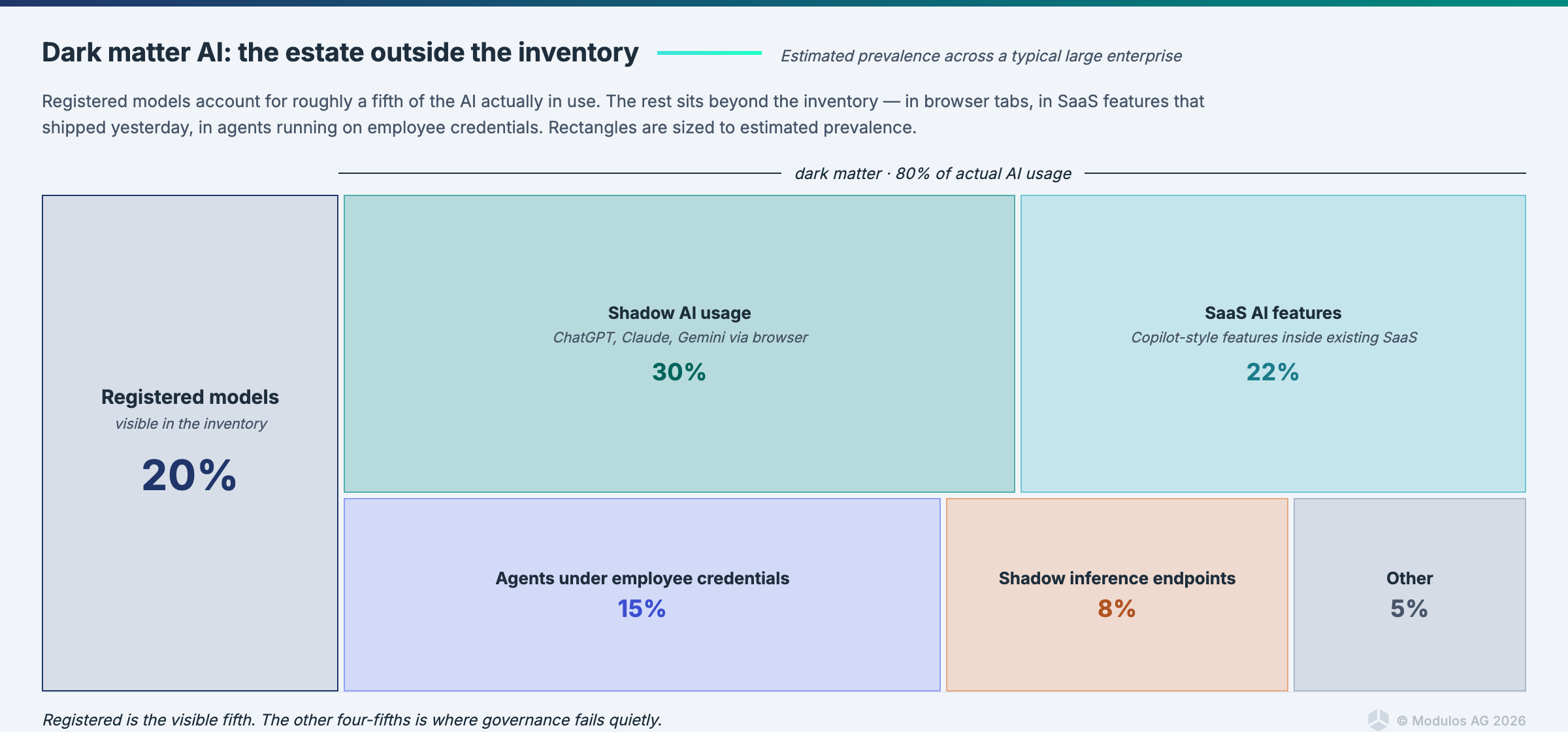
Every AI governance conversation starts with "we need to inventory our AI systems." What most organisations actually produce is a list of registered models. The registered models are the visible matter of the AI estate. They are maybe 20% of what is actually there.
The other 80% is dark matter AI. Systems that act like AI, affect outcomes like AI, and create risk like AI, but do not appear in any inventory. The term is deliberate. In astronomy, dark matter does not emit light, but we know it is there because of its gravitational effects on visible matter. In an AI estate, dark matter AI does not emit inventory entries, but we know it is there because of the risk it creates.
Four categories worth naming:
1. Shadow AI usage. Employees pasting proprietary code, customer data, or strategic documents into personal ChatGPT, Claude, or Gemini accounts. The prompt volume at most enterprises is several orders of magnitude larger than the sanctioned AI usage. None of it appears in a model registry.
2. SaaS features that quietly turned on AI. The vendors you already use added generative features in minor releases. Notion AI, Slack AI, Salesforce Einstein, Microsoft Copilot, the analytics platform your finance team runs, the CRM your sales team runs. Each of those touches data you are accountable for. Each is effectively an undocumented third-party AI system.
3. Agents running under employee credentials. An employee installs an MCP server that lets Claude act inside their email and calendar. Or an AI agent running inside a developer's IDE has commit access to production repositories. These are full AI systems with operational authority. They almost never appear on a governance dashboard.
4. Inference endpoints spun up without review. A data science team builds a prototype and deploys it behind a lightweight API. It starts serving real requests. By the time governance hears about it, it has been in production for six months.
Each category requires a different detection instrument. A data loss prevention scan catches some shadow usage. A SaaS audit catches AI features. An IAM review catches agents under credentials. A network and egress review catches the shadow inference endpoints. Most assessments do none of these. They ask the AI team to produce a model list and treat that as inventory.
How to classify AI risk across multiple frameworks at once
One of the most expensive mistakes in assessment design is running a separate classification exercise for each framework.
The right approach is to classify once and let the classification compound. The same credit scoring model is, simultaneously:
- High-risk under the EU AI Act, Annex III, falling under Article 6 and triggering full Chapter III obligations.
- An application requiring enhanced controls in the ISO 42001 AIMS.
- Sitting in the NIST AI RMF Map / Measure quadrant that demands continuous performance and fairness monitoring.
- A covered system under CBUAE AI Guidance Note Article 6 for any UAE banking operations.
- Subject to DORA operational resilience requirements if the deployment is in a financial entity under the regulation.
The overlap in controls across those frameworks is 40 to 60%. That means if your assessment produces one classification and maps it to the framework stack simultaneously, you implement a risk treatment once and it counts everywhere. If your assessment runs five separate classification exercises, you implement the same treatment five times and maintain five versions of evidence for the same underlying reality.
This is the single biggest efficiency lever in assessment design. It is also almost never what the assessment vendor offers, because the vendor's business model depends on each framework being a separate engagement.
From one-shot assessment to continuous AI governance
The assessment is the photograph. The governance platform is the film.
If all your assessment did was produce the photograph, that is a deliverable problem. If the photograph then lives in a drawer and the organisation moves on, that is a governance problem.
The way an assessment transitions to continuous governance is that every gap, control, and evidence requirement identified during the assessment becomes an object in the platform that runs the ongoing program. The controls have owners. The evidence is collected at the source from the engineering stack. Tests run on a schedule against the governance-relevant properties of your AI systems, and the results link back to the controls they satisfy.
The Modulos mechanism for this is Runtime Inspection. Sources connect to Prometheus, Datadog, GitHub, Azure, or the Modulos Client for pushed metrics. Tests defined against those metrics run on a cadence. Results flow back into the control evidence record. The governance program is operating continuously, not being recomposed from scratch each audit cycle.
If you cannot show evidence generated this month, you are not governing this month.
What to watch for when buying an AI governance assessment
This section is written with the procurement team in mind, because the procurement side of an AI governance engagement is where most of the bad decisions get made.
Watch for assessments that end with a PDF and an invoice. Ask the vendor to show you the evidence stream their methodology produces three months after the engagement closes. If there is no evidence stream, the assessment has ended, which means it failed.
Watch for assessments that do not quantify risk in euros (or your operating currency). Traffic-light dashboards are decorative. They cannot tell you whether one risk is worth 10x more treatment effort than another. Monetary quantification can. Every assessment deliverable should include at least one line item with a quantified monetary impact.
Watch for assessments that do not include agents in the inventory step. If the vendor's methodology is written around static models, it is running 2024 governance on 2026 systems. By the time the engagement finishes, the agents in your environment will have shifted the risk profile beyond what the assessment captures.
Watch for assessments that produce separate deliverables per framework. One assessment should classify once and map to all frameworks simultaneously. If the vendor is selling three engagements (one for EU AI Act, one for ISO 42001, one for NIST), you are being sold the lack of a shared control graph as a feature.
AI governance assessment FAQ
How long does a real assessment take? Two to six weeks of active engagement, depending on the size of the AI estate. The inventory step is usually the bottleneck. After that, classification and gap analysis are relatively fast if the inventory is honest.
How much does a real assessment cost? Less than you have been quoted, if the output is a platform-native evidence program rather than a report. The cost of the assessment itself is a small fraction of the cost of the governance program it seeds. The value is in the program, not the assessment.
Can we do the assessment ourselves? Yes, if the internal team has the framework expertise, access to the engineering stack, and the political cover to inventory honestly (which is harder than it sounds). Most organisations bring in external help for the first round to establish the baseline and then carry it forward with a platform.
What if our leadership wants a PDF? Produce one. Just do not stop there. The PDF is the executive summary of the evidence program. The evidence program is the actual deliverable.
Is this different from an ISO 42001 gap assessment? An ISO 42001 gap assessment is a subset of an AI governance assessment. It looks at your AIMS against the 42001 clauses and Annex A controls. A governance assessment covers ISO 42001, plus the EU AI Act obligations, plus NIST AI RMF, plus any sectoral frameworks that apply, plus the systems themselves. The scope is substantially broader.
What about Scout and the Modulos AI agents? Can they run the assessment for me? They can accelerate it substantially. Scout is grounded in your project context and can draft control assessments, extract evidence from connected data sources, and flag gaps. The Evidence agent suggests mappings. The Control assessment agent produces structured drafts. The review and approval step stays human. That is the point. Agent outputs are suggestions. Humans remain accountable.
Closing
The institutions that run continuous assessment are already having a different conversation with their supervisors. They are showing evidence generated this month, quantified risk in euros, and control status changes that went through the review workflow this week.
The ones still buying point-in-time assessments will have an expensive retrofit in front of them when the audit arrives. The Omnibus will move deadlines. The obligations will not change. The organisations with infrastructure will absorb whatever trilogue produces. The organisations with PDFs will refactor.
Choose accordingly.
Ready to see how Modulos handles AI governance assessment? Request a demo and we will walk you through how the AI governance platform turns a one-off deliverable into a living control graph against the global AI compliance guide and the guide to AI governance.
Cross-links: guide to AI governance, AI governance platform, global AI compliance guide.


